Продолжение обзора офф-лайн браузеров
Вот мы и подошли непосредственно к самой задаче, в целях конфиденциальности, я не буду указывать сайт который я выкачивал, назовем его условно www.enciklopedia.com. В чем заключается особенность это сайта? И почему я его так долго качал?
Все обычные сайты состоящие из html страничек скачиваются очень просто, достаточно задать программе с помощью
мастера с какого начального адреса качать, максимальную глубину следования по ссылкам, типы файлов для закачки и прочие настройки и он очень легко и быстро выкачается.
Я же столкнулся с динамическим сайтом, построенным на CGI скриптах. Суть его в следующем данные каждой странички хранятся в базе данных, когда вы делаете переход по ссылке скрипт передает запрос базе та в свою очередь выдает скрипту необходимые данные указанной страницы, а скрипт их принимает и формирует хтмл-ку и выдает вашему браузеру. Плюс ко всему этому на страничках изобилуют Java скрипты и прочие радости.
И в добавок доступ к сайту производится через ваш персональный логин и пароль.
В итоге ссылка для перехода на страницу Х выглядит следующим образом:
www.enciklopedia.com/cgi-bin/enc.cgi=r_GHgjasdsgjs&id=155&display
данные о вашей сессии на сайте запоминаются в cookie файлах.
При первой закачке я с предусмотрительностью поставил глубину = 30. В итоге просидел с закачкой 2 дня пока, счетчик файлов очереди не показал мне "Что еще осталось закачать 500658 файлов", это при том, что уже было закачано около 250000 файлов. После этого я все остановил и начал искать причину такого неимоверного раздутия списка.
Я поставил глубину = 5 в итоге выяснил что этого достаточно для закачки всех нужных мне страниц. Но их количество в очереди все равно было очень большим (около 300 тыс.)
Тогда я снова полез в настройки программы. В "Свойствах проекта" я нашел замечательную вещь как "Фильтры URL" далее "Имя файла" и установил на "Произвольная конфигурация". Далее я в список "Маски исключения имен файлов" вбил следующие значения:
Все обычные сайты состоящие из html страничек скачиваются очень просто, достаточно задать программе с помощью
мастера с какого начального адреса качать, максимальную глубину следования по ссылкам, типы файлов для закачки и прочие настройки и он очень легко и быстро выкачается.
Я же столкнулся с динамическим сайтом, построенным на CGI скриптах. Суть его в следующем данные каждой странички хранятся в базе данных, когда вы делаете переход по ссылке скрипт передает запрос базе та в свою очередь выдает скрипту необходимые данные указанной страницы, а скрипт их принимает и формирует хтмл-ку и выдает вашему браузеру. Плюс ко всему этому на страничках изобилуют Java скрипты и прочие радости.
И в добавок доступ к сайту производится через ваш персональный логин и пароль.
В итоге ссылка для перехода на страницу Х выглядит следующим образом:
www.enciklopedia.com/cgi-bin/enc.cgi=r_GHgjasdsgjs&id=155&display
данные о вашей сессии на сайте запоминаются в cookie файлах.
При первой закачке я с предусмотрительностью поставил глубину = 30. В итоге просидел с закачкой 2 дня пока, счетчик файлов очереди не показал мне "Что еще осталось закачать 500658 файлов", это при том, что уже было закачано около 250000 файлов. После этого я все остановил и начал искать причину такого неимоверного раздутия списка.
Я поставил глубину = 5 в итоге выяснил что этого достаточно для закачки всех нужных мне страниц. Но их количество в очереди все равно было очень большим (около 300 тыс.)
Тогда я снова полез в настройки программы. В "Свойствах проекта" я нашел замечательную вещь как "Фильтры URL" далее "Имя файла" и установил на "Произвольная конфигурация". Далее я в список "Маски исключения имен файлов" вбил следующие значения:
- *print*
- *mail*
- *comment*
- *browse&n*
- *popup*
- *search*
- *tab=browse*
- *query$
- *f=1*
- *enc.cgi?n=*
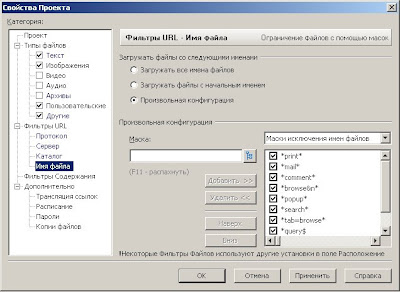
Зачем я это сделал. При изучении первой закачки я обнаружил что одни и теже страницы дублируются по 5 раз, оказалось, что скрипт обращается к одной и тоже информации в базе только разными запросами. Звездочки (*) перед словами означают что в адресе странички перед и после указанного слова может быть любое количество любых символов. Знак доллара ($) означает, что фильтруемое слово стоит в конце адреса.
Например ссылки:
www.enciklopedia.com/cgi-bin/enc.cgi=r_GHgjasdsgjs&id=155&display
www.enciklopedia.com/cgi-bin/enc.cgi=query&browse=xsdsds&id=155
в итоге приводили к одной и той же страничке. Тут возникла вторая проблема на сайте есть большое количество терминов, которые описываются каждый на отдельной странице. Так вот добраться к этим терминам можно путем перехода на страницу с их списком. При переходе по запросу со словом query списки отображаются в постраничном режиме, а со словом display в общем виде т.е. все несколько тысяч терминов на одной странице точнее ссылки на них. Оказалось, что постраничный режим вообще не подходит для закачки, так как скрипт успевает динамически поменять идентификаторы ссылок на страницы, в итоге в список исключений я добавил слова browse и query, что касается слов print, mail, comment, popup и search, то они так же дублируют страницы. Последнее слово связано с тем, что я ставил опцию "Вычислять выражения в скриптах", отказаться от нее нельзя так как сайт изобилует ява скриптами, но при этом программа пытаясь их вычислять пользовалась поиском по сайту и плодила дубликаты. А версии страниц преобразованные для печати и отправки по почте и всплывающие в другом окне мне также не нужны.
Тут правда возникла и другая сторона медали. На всех страницах сайта, есть ява-меню навигации, так вот в меню и стоят ссылки к общим спискам терминов, а с общих списков уже идет навигация по частным страницам. Но весь прикол в том, что ссылки из меню на эти списки содержат слово query, а я его уже добавил в черный список, как быть? Решение простое я добавил эти ссылки в адреса URL главного проекта (закладка "Проект" в "Свойствах Проекта") и они закачались принудительно, а с них уже программа начала искать другие страницы. И еще один нюанс, ссылки имели вид:
Например ссылки:
www.enciklopedia.com/cgi-bin/enc.cgi=r_GHgjasdsgjs&id=155&display
www.enciklopedia.com/cgi-bin/enc.cgi=query&browse=xsdsds&id=155
в итоге приводили к одной и той же страничке. Тут возникла вторая проблема на сайте есть большое количество терминов, которые описываются каждый на отдельной странице. Так вот добраться к этим терминам можно путем перехода на страницу с их списком. При переходе по запросу со словом query списки отображаются в постраничном режиме, а со словом display в общем виде т.е. все несколько тысяч терминов на одной странице точнее ссылки на них. Оказалось, что постраничный режим вообще не подходит для закачки, так как скрипт успевает динамически поменять идентификаторы ссылок на страницы, в итоге в список исключений я добавил слова browse и query, что касается слов print, mail, comment, popup и search, то они так же дублируют страницы. Последнее слово связано с тем, что я ставил опцию "Вычислять выражения в скриптах", отказаться от нее нельзя так как сайт изобилует ява скриптами, но при этом программа пытаясь их вычислять пользовалась поиском по сайту и плодила дубликаты. А версии страниц преобразованные для печати и отправки по почте и всплывающие в другом окне мне также не нужны.
Тут правда возникла и другая сторона медали. На всех страницах сайта, есть ява-меню навигации, так вот в меню и стоят ссылки к общим спискам терминов, а с общих списков уже идет навигация по частным страницам. Но весь прикол в том, что ссылки из меню на эти списки содержат слово query, а я его уже добавил в черный список, как быть? Решение простое я добавил эти ссылки в адреса URL главного проекта (закладка "Проект" в "Свойствах Проекта") и они закачались принудительно, а с них уже программа начала искать другие страницы. И еще один нюанс, ссылки имели вид:
http://www.enciklopedia.com/cgi-bin/enc.cgi?pid=5756&a=query
экспериментальным путем я установил, что эта ссылка загружала список терминов в постраничном режиме, а для загрузки полного списка надо было добавить в конец адреса:
&all=yes
т.е. ссылка принимала вид:
http://www.enciklopedia.com/cgi-bin/enc.cgi?pid=5756&a=query&all=yes
экспериментальным путем я установил, что эта ссылка загружала список терминов в постраничном режиме, а для загрузки полного списка надо было добавить в конец адреса:
&all=yes
т.е. ссылка принимала вид:
http://www.enciklopedia.com/cgi-bin/enc.cgi?pid=5756&a=query&all=yes
это пришлось сделать вручную.
В конечном результате, я полностью выкачал свой сайт, при этом он был полностью работоспособный, никаких глюков в ссылках, а общее количество файлов составило - 35000. Что не может не радовать! ;)
Обобщающий совет напоследок:
При закачке динамических сайто делайте пробную закачку, просмотрите её, проанализируйте, настройте, если надо, фильтры и только потом ставьте на загрузку. Когда вы полностью все настроите и проверите, сделайте новый проект, поскольку я заметил, что программа не очищает кеш проекта при повторном его старте в режиме "Перезапустить загрузку".
Пару слов о замеченных глюках...
Когда вы качаете громадные сайты, с количеством страниц более 130 тыс., то в настройка программы надо поставить галочку "Предотвращать переполнение каталогов". Иначе все файлы будут сохраняться в один каталог и в результате Offline Explorer просто виснет и вылетает.
В конечном результате, я полностью выкачал свой сайт, при этом он был полностью работоспособный, никаких глюков в ссылках, а общее количество файлов составило - 35000. Что не может не радовать! ;)
Обобщающий совет напоследок:
При закачке динамических сайто делайте пробную закачку, просмотрите её, проанализируйте, настройте, если надо, фильтры и только потом ставьте на загрузку. Когда вы полностью все настроите и проверите, сделайте новый проект, поскольку я заметил, что программа не очищает кеш проекта при повторном его старте в режиме "Перезапустить загрузку".
Пару слов о замеченных глюках...
Когда вы качаете громадные сайты, с количеством страниц более 130 тыс., то в настройка программы надо поставить галочку "Предотвращать переполнение каталогов". Иначе все файлы будут сохраняться в один каталог и в результате Offline Explorer просто виснет и вылетает.

Теперь, поскольку сайт требует авторизацию и сохраняет данные о сессии в куки в настройках надо включить - "Использовать MS IE cookies" и "Идентифицировать как - Microsoft Internet Explorer":

Количество соединений, вы ставите на ваше усмотрение, в зависимости от выносливости сервера сайта.
Когда Вы все закачаете, необходимо сделать экспорт проекта в какой-нибудь локальный каталог.
Делается это с помощью мастера Экспорта.
Запускаете его: Файл -> Экспорт и в настройка указываете необходимые вам параметры, например как у меня:
Когда Вы все закачаете, необходимо сделать экспорт проекта в какой-нибудь локальный каталог.
Делается это с помощью мастера Экспорта.
Запускаете его: Файл -> Экспорт и в настройка указываете необходимые вам параметры, например как у меня:
 Он-лайн ссылки и исходные URL мне не нужны я их и не ставил. Файл содержимого по вашему усмотрению. "Ускоренный экспорт" не подходит если вы ставили галочку "Защита от переполнения каталогов" - программа неправильно обрабатывает ссылки.
Он-лайн ссылки и исходные URL мне не нужны я их и не ставил. Файл содержимого по вашему усмотрению. "Ускоренный экспорт" не подходит если вы ставили галочку "Защита от переполнения каталогов" - программа неправильно обрабатывает ссылки.Единственное, что не понравилось, так это скорость экспорта - она очень низкая. Мои 35 тыс. файлов обрабатывались около трех часов. Я понимаю что в век Интеловских двухядерных процессоров можно уже не думать об оптимизации кода программы, ну а куда деваться нам? людям с 1,6Ггц Дюронами и 512 Мб оперативки ? :)
Вообщем над этим вопросом я думаю разработчиком следует всерьез подумать...
В целом же программа очень достойная и как я говорил раньше, по моему скромному мнению, лучшая в своем классе.
На счет других форматов экспорта поговорим в следующей статье, где я буду подробно рассказывать как лучше просматривать выкачанный сайт на локальном компьютере.
Ну а пока все, до встречи в след. статье.... :) Приятных закачек!
Комментарии